
The Story
My wife and I run a nonprofit called Inquire Higher, an organization that provides college, career, and networking resources to Black students and early professionals. To increase college access, we introduced the Black Student Success Scholarship in 2021. Before I started working with data regularly, I always thought it would be helpful to compare the applicant years to each other in a more efficient way than flipping back and forth between spreadsheets. After collecting four years of data from the applications and understanding how to organize and visualize them, I decided to build a dashboard.
***LINK TO THE FULL DASHBOARD BELOW***
Objective
Create a dashboard for the scholarship application data for 2021-2024 to:
1) understand who is applying for the scholarship
2) how the scholarship is reaching the students, and
3) create targeted application volume goals and specific efforts to achieve them
Tools Used
Process
1) Extract the data. I built the scholarship application itself in Google Forms for its administrative simplicity and flexibility, as well as its familiarity to most users. Data from the application submissions were transferred to a spreadsheet in Google Sheets upon completion. After the deadline, the Google Sheets spreadsheet was manually exported to Excel for transformation. Each year of applications was exported, resulting in four separate files.
2) Transformations. All the transformations were performed in Excel. The first part of this step was to identify the data columns I wanted to include in the dashboard. Since 2021, the data collected, and method of the collection, has expanded and improved. For example, the State column went from a freeform field to a selection field in 2023 to eliminate the spelling errors and variety of the entries’ full names and abbreviations found in the 2021 and 2022 data. Furthermore, the number of fields/questions (and data columns as a result) increased from 31 in 2021 to 39 in 2024. I had to be mindful of how I wanted to handle the columns I selected for the years during which they didn’t exist in the application.
STEP 1: COLUMN SELECTION
Here are the existing fields I selected:
Timestamp – date and time of the form submissions (generated by Google Forms)
City – city of residence
State – state of residence
Zip – zip code
Gender – gender identity
Citizenship – citizenship at the time of submission
StudentType – school level (High School or College)
School – committed or current college/university
Major – area of study
GPA – unweighted GPA at the time of submission
Involvement1 – first type of activity outside of school (Extracurricular Activity or Community Service)
Position1 – type of position held within the applicant’s first activity (General Member, Executive Board, or Founder; multiple selections allowed)
Involvement2 – second type of activity outside of school
Position2 – type of position held within the applicant’s second activity
Involvement3 – third type of activity outside of school
Position3 – type of position held within the applicant’s third activity
FoundScholarship – where or how the applicant found the scholarship
FoundScholarshipOther – additional information about where or how the scholarship was found
Here are the new fields I created:
StudentID – unique identifier
Year – application year
Month – month of submission
DayOfWeek – day of submission
CareerPath – assigned categories based on the applicant’s major (categories adopted from the O*NET Program’s career clusters)
RawGPA – original “GPA” column renamed
Scale – determined GPA scale
GPA – RawGPA converted to the 4.0 scale
Extracurricular – total number of applicant’s extracurricular activities
CommunityService – total number of applicant’s community service activities
TotalActivities – total number of all applicant’s activities
General – total number of applicant’s general membership positions
Executive – total number of applicant’s executive board positions
Founder – total number of applicant’s founding member/creator/organizer positions
Other1 – original “FoundScholarshipOther” column renamed
Other2 – second set of additional information about where or how the scholarship was found
STEP 2: TRANSFORMING THE INDIVIDUAL FILES
To unify the format of each separate application year file, I completed the following transformations:
ALL YEARS
Duplicate submissions. First, I created a column that put the applicant’s name in a “Last Name, First Name” using the CONCAT function and TRIM to remove any leading or trailing spaces. The data was sorted in alphabetical order based on the new name column. Next, I used the ISNONTEXT, IF, and COUNTIF functions to identify duplicate applications based on the new name column. The formula also labeled the latest entries as “TRUE,” so I removed all the “FALSE” duplicate submissions with the assumption that the former submissions are the most complete.
Added a unique identifier. I used the CONCAT, TEXT, and MID functions to create unique identifier for each application. I also included two digits at the end of each ID to designate the application year.
Data organization. After the year-specific transformations were completed, the unnecessary columns were deleted. The remaining columns were renamed and reordered. All the data was placed in an Excel table named “Applicants.”
2021
Added the School column. There was a “Top Three College Choices” column where applicants entered up to three schools in this field. Since most applicants who entered multiple schools used a comma, space, or semi-colon to separate them, I used the IF, ISNUMBER, SEARCH, and TEXTBEFORE functions to first check the entry for each delimiter. If one existed, the formula returned the school before the first delimiter. If not, which covered most of the remaining entries, the only school within the entry was returned. There were a handful of one-off data that required manual intervention.
Added the StudentType column. This data was not collected in 2021, so the column was added and filled with “High School” since all the applicants in 2021 were high school students.
Added the Citizenship, Gender, Involvement 1-3, and Position 1-3 columns. This data was not collected in 2021, so the columns were added and filled with “N/A” to represent the absence of the data.
2022
Added the StudentType column. This data was not collected in 2022, so the column was added and filled with “High School” since all the applicants in 2022 were high school students.
Added the Gender column. This data was not collected in 2022, so the columns were added and filled with “N/A” to represent the absence of the data.
2023 & 2024
Created a School column based on StudentType. 2023 was the first year when both high school and college students could apply for the scholarship. In the application, they identified whether they were in high school or college, where they were attending at the time of submission, and their #1 school choice. The #1 school choice question applied to the high school applicants, so the college applicants were instructed to enter “N/A” for this field. I used the IF function to read the StudentType entry. If the field read “College,” then the Current School was returned, If not, then the #1 School Choice was returned. There were a handful of one-off data that required manual intervention.
STEP 3: COMBINING THE INDIVIDUAL FILES
After the individual data files were transformed and unified, I combined the files in Excel using the Get Data feature for further transformations. The files were saved to a designated folder before starting this process.

I selected the “Combine and Load” option and used the “Applicants” table as the parameter to query and combine the data from the files.


STEP 4: TRANSFORMING THE COMBINED FILE
Here is the first set of transformations completed on the combined data. These transformations were generally completed with one formula:
Year, Month, and DayOfWeek – TEXT function to extract the appropriate part of the Timestamp
Zip – LEFT function to return the first five digits of the entry
Extracurricular & CommunityService – COUNTIF function against the Involvement columns to count the number of each type of activity
TotalActivities – SUM of the Extracurricular and CommunityService columns
General, Executive, and Founder – COUNTIF function against the Position columns to count the number of each type of position
The second set of transformations on the combined data required multiple steps to complete:
City
1) I used the UNIQUE function to return an array of the distinct entries from the original data and placed them in a new Excel table.
2) The PROPER and TRIM functions against the unique entries returned the data without leading and/or trailing spaces and proper capitalization into a second column table.
3) Manual updates were performed for one-off transformations (e.g. an original entry of “OKC” updated to “Okc” in Step 2 followed by a final update of “Oklahoma City.”
4) The XLOOKUP function matched the original entries to return the cleaned city names to a new City column in the combined data.
State
I used the UNIQUE function to return an array of the distinct entries from the original 2021 and 2022 data and placed them in a new Excel table. As previously mentioned, the State data was standardized in the application for data integrity purposes.
2) The PROPER and TRIM functions against the unique entries returned the data without leading and/or trailing spaces and proper capitalization into a second column table.
3) Manual updates were performed for one-off transformations.
4) Third and fourth columns were added with the correct spellings of the state/territory names and abbreviations.
5) The XLOOKUP function matched the original entries to return the cleaned state names to a new State column in the combined data.
School
1) The PROPER and TRIM functions against the unique entries returned the data without leading and/or trailing spaces and proper capitalization into a second column table. Furthermore, these functions were nested within a series of nested SUBSTITUTE functions to replace the capitalized conjunctions and prepositions with their lowercase counterparts.
2) I used the UNIQUE function to return an array of the distinct entries from the original data and placed them in a new Excel table.
3) A third column was added using the COUNTIF function to identify duplicate data from the trimmed columns.
4) I added a fourth column and used background knowledge and research to standardize the names of the colleges and universities. For example, entries of “UCLA,” “University of California – Los Angeles,” and “UC Los Angeles” were standardized to “University of California-Los Angeles.”
5) The XLOOKUP function matched the original entries to return the cleaned school names to a new School column in the combined data.
Major
1) I used the UNIQUE function to return an array of the distinct entries from the original data and placed them in a new Excel table.
2) The PROPER and TRIM functions against the unique entries returned the data without leading and/or trailing spaces and proper capitalization into a second column table. Furthermore, these functions were nested within a series of nested SUBSTITUTE functions to replace the capitalized conjunctions and prepositions with their lowercase counterparts.
3) A third column was added using the COUNTIF function to identify duplicate data from the trimmed columns.
4) I added a fourth column and used background knowledge and research to standardize and simply the names of majors. For example, entries of “African American Studies” and “African American Cultural Studies” were standardized to “African American Studies.”
5) The XLOOKUP function matched the original entries to return the cleaned majors names to a new Major column in the combined data.
FoundScholarship and Subcategories
1) I used the UNIQUE function to return an array of the distinct entries from the “FoundScholarshipOther” column and placed them in a new Excel table.
2) A second column was added to standardize the freeform entries for the applicants who select “Other” when answering the question, “How did you find out about the scholarship. The entries were standardized to either one of the existing, main responses (Advertisement, Internet Search, Scholarship Search Engine, Social Media, Website, Word of Mouth, Other) or a new grouping of subcategories associated with the some of the main categories:
Scholarship Search Engine – various websites
Social Media – various social media platforms
Word of Mouth – Family/Friend, Colleague, Mentor, Educator, Church
Other – Counselor/Advisor, School, Outside Organization, Email List
This was a manual process due to relatively few entries and the subjectivity of the categorization.
3) The XLOOKUP function matched the original entries to return the cleaned data to the FoundScholarship and its associated subcategory columns, labeled “Other1” and “Other2,” in the combined data.
3) Load the data into Power BI. Here were my three focus areas for the dashboard:
Reflection of the application. I wanted to ensure that the dashboard was an accurate depiction of the scholarship application. I split the dashboard into three major sections: Overview that details data about the application volume, Academics that details the relationships between the applicants’ schools, majors, and residences, and Activities that details the applicants’ involvement outside the classroom.
Interactivity. I drew my own insights from the data, but giving others the opportunity to do the same was part of my thought process when building the dashboard. Filled maps, a tree map, and corresponding column and pie charts were some of the elements I used to achieve this.
Consistent branding and graphic positioning. I’m not the most visually adept person, but I am a stickler for visual consistency. As I was building, I made good note of the exact positions of each element and make sure any overlapping of visuals between pages had seamless transitions. In addition, I used Coolers to find a color palette that matched our logo and incorporate throughout the entire dashboard.
Notable Findings
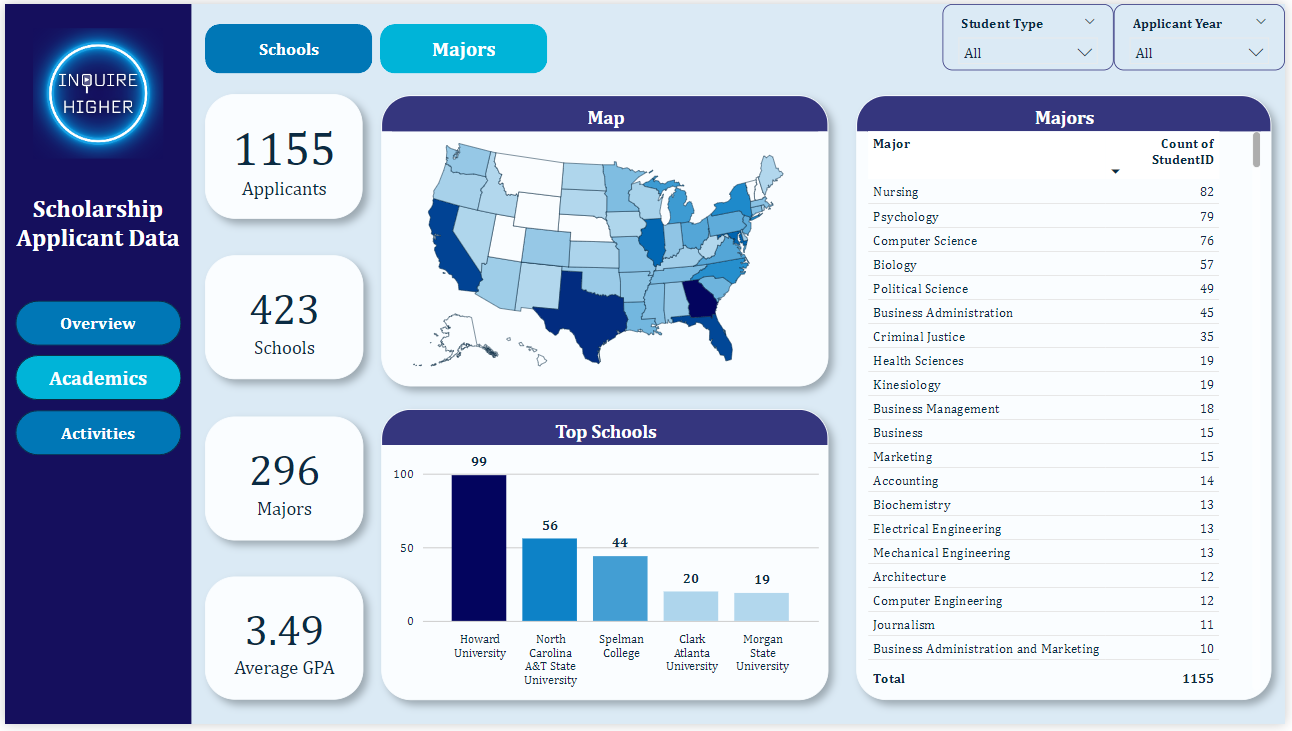
HBCUs. 8 out of the top 10 schools where the most applicants commit to and/or attend are HBCUs. This could be an indicator that most of the students who have pursued the scholarship either attend or plan to attend a historically Black college or university. When thinking about new content to create, aligning the information about HBCUs may be beneficial to our audience.
Howard University. Howard University has been the top school choice among all applicants and within each application year. This could provide a chance to partner with HU or any of the top schools in our applicant pool to develop exclusive opportunities for their students.
Top 5 Majors. Nursing, Psychology, Computer Science, Biology, and Political Science account for 30% of all applicants’ major choices. Similarly, we, as a nonprofit, could create initiatives that focus on one of these majors, such as an additional scholarship or networking event.
Scholarships.com. A large majority of the students who used scholarship search engines found the scholarship on Scholarships.com. In the past, we made the effort to post the scholarship on as many search engines as possible. Given the large amount of visibility thanks to Scholarships.com and the limited number of search engines listed from the applications, this finding may allow us to reduce our posting efforts and re-direct the increased capacity to enhance the scholarship in other ways. Furthermore, HBCUConnect was the second most listed scholarship search, and the scholarship made it to their database without us posting there.
Reflection
Transformations. Cleaning the data was one of my favorite parts of this project. Incorporating patience and forward-thinking with the technical skills themselves was a very rewarding process. It also gave me the confidence to seek ways to transfer the transformation skills and methods to other tools such as Power Query and Python.
Dashboard Design. Through learning design concepts and understanding Power BI’s capabilities through trial and error, the initial design of the dashboard was significantly different than the final version. It went from a one-page dashboard to seven pages to three pages. I also learned the lesson of understanding when a design is good enough. I got so deep into the weeds of the features that kept finding ways to make something “better.” Finally, my desire to finish kicked it and allows me to better define the goals and endpoint of the design.

Dual Role as the Analyst and Stakeholder. This was an interesting position to be in as I was essentially creating a dashboard for myself. So I already knew my audience from the beginning. The advantage of this is to conceptualize and build the dashboard simultaneously. However, I was limited to my own perspective for improvements. Overall, it was a good learning experience and helped me better understand ways to communicate to stakeholders and creating a checklist out of the information they want for a dashboard design.
Future Enhancements
Review and update the application to improve the initial data collection. Every year, I review the application questions and the responses I see to determine if the wording is clear for the applicants. One question I would like to follow the GPA question is asking what scale their GPA is based upon. This would prevent me from having to guess before equating the entry to a 4.0-scale GPA.
Automate the ETL process to increase efficiency. I would like to build Python scripts to clean the data in the same way I did in Excel and load it into a database. This may require a data warehouse with a medallion architecture so I can maintain a copy of the data in its raw form.
Database storage. Instead of in Excel files, I would like to store the application data into a relational database for efficient storage of the and future queries of the cleaned data. The cleaned data is in one single table, so I may want to consider normalizing the data to gain more querying options for further analysis.
Full Dashboard
To interact with the full dashboard and explore the makeup of our scholarship’s applicants, click here.
